Attention 注意力机制
Attention 的本质
Attention(注意力)机制的核心逻辑就是 从关注全部到关注重点,将有限的注意力集中在重点信息上从而节省资源,快速获得最有效的信息
Attention 的优点
-
参数少
模型复杂度跟 CNN 和 RNN 相比,复杂度更小,参数也更少。所以对算力的要求也就更小。
-
速度快
Attention 解决了 RNN 不能并行计算的问题。Attention 机制每一步计算不依赖于上一步计算的计算结果,因此可以和 CNN 一样并行处理。
-
效果好
以前存在的问题:长距离的信息会被弱化。
Attention 能抓住重点,不丢失重要的信息。
注意力分布
为了从 N 个输入向量 [x_1,· · ·,x_N] 中选择出和某个特定任务相关的信息,我们需要引入一个和任务相关的表示,称为查询向量 (Query Vector ),并通过一个打分函数来计算每个输入向量和查询向量之间的相关性。 给定一个和任务相关的查询向量 q ,我们用注意力变量 z 来表示被选择信息的索引位置,即 z=n 表示选择了第 n 个输入向量,为了方便计算,采用了一种“软性”的信息选择机制,首先计算在给定q 和 X 下,选择第 i 个输入向量的概率
其中 称为注意力分布 (Attention Distribution)s(x,q) 为注意力打分函数,可以使用以下几种方式来计算:
其中 W,U,V 为可学习的参数,D 为输入向量的维度。
加权平均 注意力分布 可以解释为在给定任务相关的查询 q 时,第 n 个输入向量的受关注的程度。采用软性的信息机制对输入信息进行汇总,即:
Attention 原理
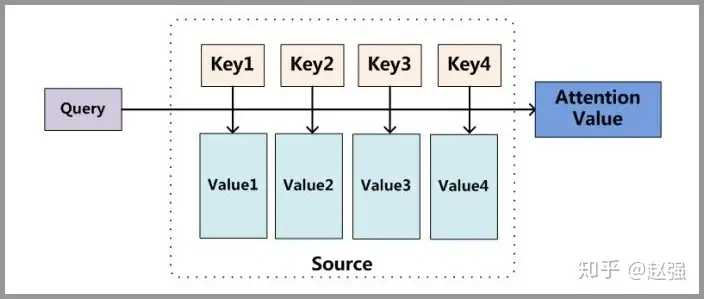
分为三步:
- query 和 key 进行相似度计算,得到每个 key 和对应的 Value 的权值。
- 将权值进行归一化,得到直接可用的权重。
- 将权重和 value 进行加权求和。
公式如下:
其中 =||Source|| 为 Source 的长度。
Attention 计算过程
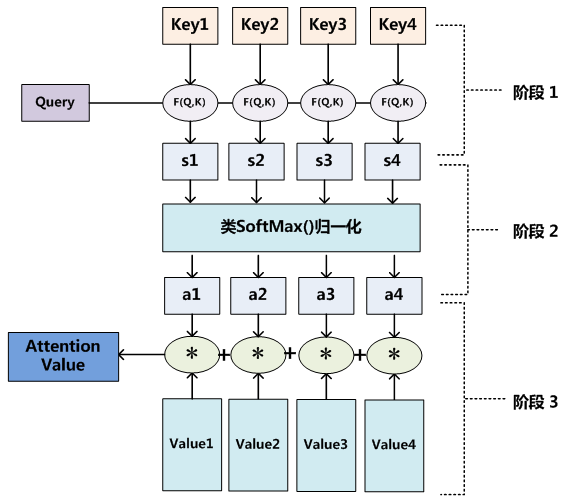
在第一个阶段,可以引入不同的函数和计算机制,根据 Query 和某个 ,计算两者的相似性或者相关性,最常见的方法包括:求两者向量点积、求两者的向量 Cosine 相似性、或者通过引入额外的神经网络来��求值,即如下
第一阶段产生的分值根据具体产生的方法不同其数值取值范围也不一样,第二阶段引入类似 SoftMax 的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为 1 的概率分布;另一方面也可以通过 SoftMax 的内在机制更加突出重要元素的权重。及一般采用如下公式计算:
第二阶段的计算结果 即 对应的权重系数然后进行加权求和即可得到 Attention 数值:
通过如上三个阶段的计算,即可求出针对 Query 的 Attention 数值,目前绝大多数都符合上述的三个阶段抽象计算过程。
Self Attention 模型
Attention 机制发生在 Target 的元素 Query 和 Source 中的所有元素之间。而 Self Attention 顾名思义,指的不是 Target 和 Source 之间的 Attention 机制,而是 Source 内部元素之间或者 Target 内部元素之间发生的 Attention 机制,也可以理解为 Target=Source 这种特殊情况下的注意力计算机制。

自注意力模型的计算过程
假设输入序列为 X=[x_1,. . . ,x_N] ,输入序列为 H=[h_1,. . .,h_n] ,自注意力模型的具体计算过程如下: (1)对于每个输入 X_i ,首先将其线性映射到三个不同的空间,得到 查询向量 、键向量 、值向量 (2)通过上述的 (1) 式和 softmax 计算出 H 自注意模型计算的权重 只依赖于 和 的相关性,而忽略了输入信息的位置信息。在单独使用时,自注意模型一般需要加入位置编码信息来进行修正,自注意力模型可以扩展为多头自注意力 模型,在多个不同的投影空间中捕捉不同的交互信息。
Attention 的类型
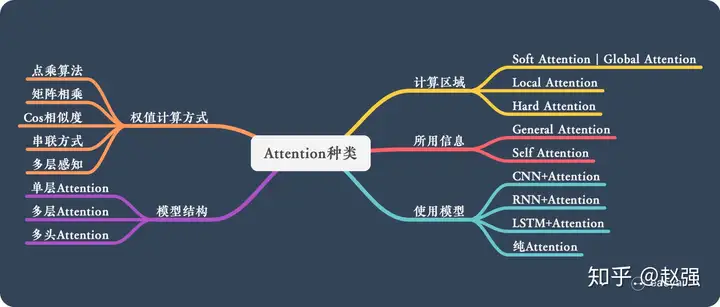
图像处理中的注意力机制
综述:图像处理中的注意力机制 - 知乎 (zhihu.com)
SENET(通道域)
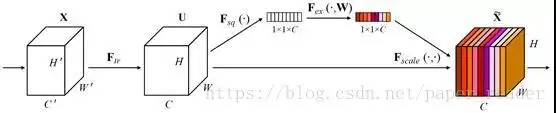 中间的模块就是 SENet 的创新部分,也就是注意力机制模块。这个注意力机制分成三个部分:挤压 (squeeze),激励 (excitation),以及 scale(attention)。
中间的模块就是 SENet 的创新部分,也就是注意力机制模块。这个注意力机制分成三个部分:挤压 (squeeze),激励 (excitation),以及 scale(attention)。
流程:
- 将输入特征进行 Global AVE pooling,得到 1_1_ Channel
- 然后 bottleneck 特征交�互一下,先压缩 channel 数,再重构回 channel 数
- 最后接个 sigmoid,生成 channel 间 0~1 的 attention weights,最后 scale 乘回原输入特征
Residual Attention Network(混合域)
提出注意力 mask 可以看作是每一个特征元素的权重。通过给每个特征元素都找到其对应的注意力权重,就可以同时形成了空间域和通道域的注意力机制
这种注意力机制的创新点在于提出了残差注意力学习 (residual attention learning),不仅只把 mask 之后的特征张量作为下一层的输入,同时也将 mask 之前的特征张量作为下一层的输入,这时候可以得到的特征更为丰富,从而能够更好的注意关键特征。
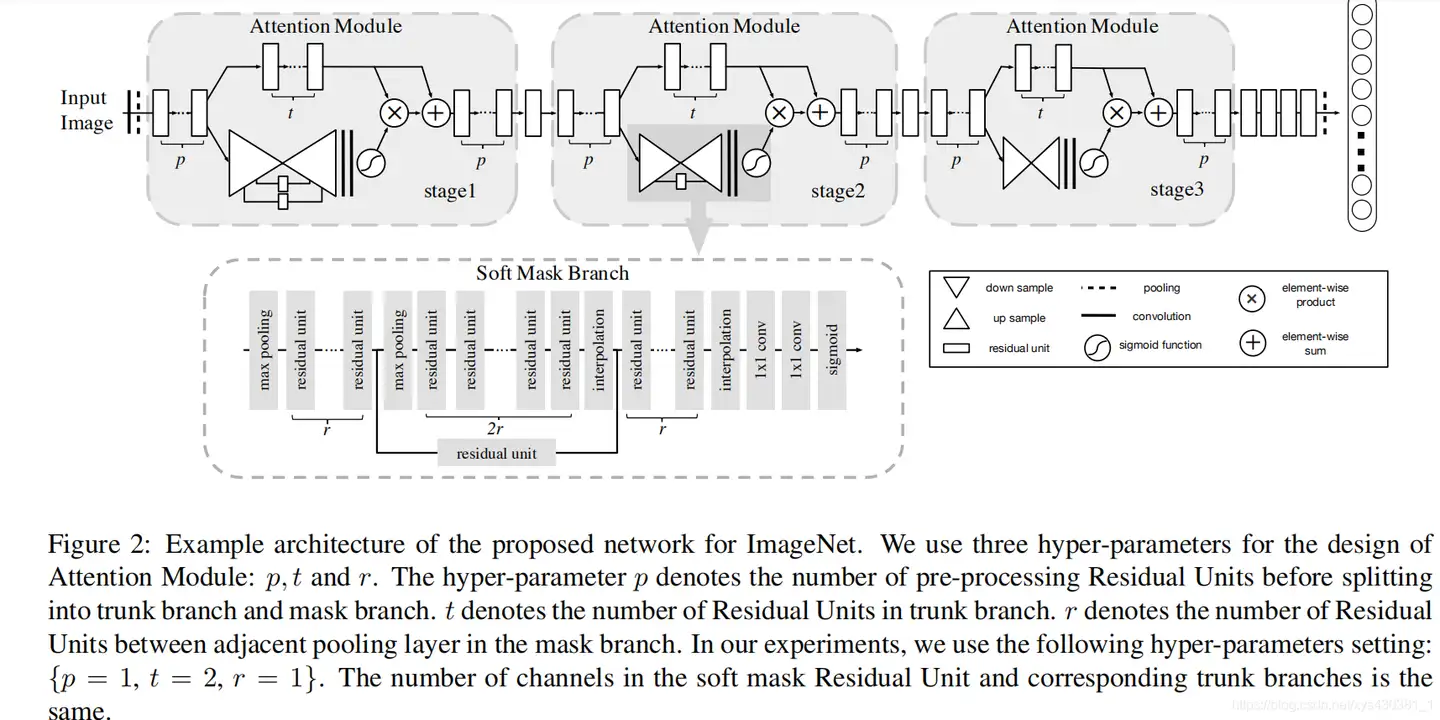 每一个注意力模块可以分成两个分支 (看 stage2),上面的分支叫主分支 (trunk branch),是基本的残差网络 (ResNet) 的结构。而下面的分支是软掩码分支 (soft mask branch),而软掩码分支中包含的主要部分就是残差注意力学习机制。通过下采样 (down sampling) 和上采样 (up sampling),以及残差模块 (residual unit),组成了注意力的机制。
残差注意力机制是:
每一个注意力模块可以分成两个分支 (看 stage2),上面的分支叫主分支 (trunk branch),是基本的残差网络 (ResNet) 的结构。而下面的分支是软掩码分支 (soft mask branch),而软掩码分支中包含的主要部分就是残差注意力学习机制。通过下采样 (down sampling) 和上采样 (up sampling),以及残差模块 (residual unit),组成了注意力的机制。
残差注意力机制是:
H 是注意力输出,F 是上一层的图片张量特征,M 是软掩码的注意力参数,这就构成了残差注意力模块,能将图片特征和加强注意力之后的特征一同输入到下一模块中。F 函数可以选择不同的函数,就可以得到不同的注意力域的结果:
- f1 是对图片特征张量直接 sigmoid 激活函数,就是混合域的注意力;
- f2 是对图片特征张量直接做全局平均池化(global average pooling),所以得到的是通道域的注意力(类比 SENet);
- f3 是求图片特征张量在通道域上的平均值的激活函数,类似于忽略了通道域的信息,从而得到空间域的注意力。
Non-local Neural Networks
为了关注全局其他片区对当前区域的贡献。
non-local blocks 要做的是,捕获这种 long-range 关系:对于 2D 图像,就是图像中任何像素对当前像素的关系权值;对于 3D 视频,就是所有帧的所有像素,对当前帧的像素的关系权值。
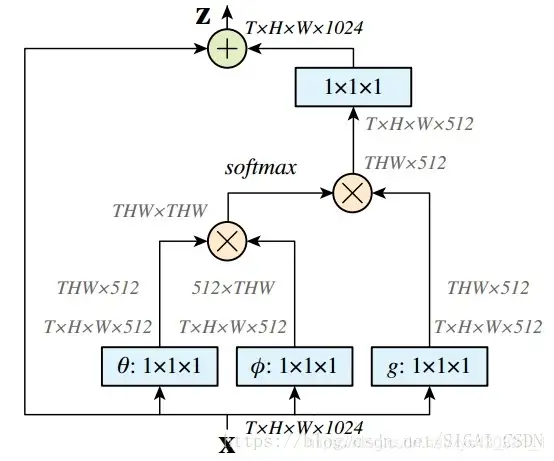 DL 框架中最好实现的 Matmul 方式:
DL 框架中最好实现的 Matmul 方式:
- 首先对输入的 feature map X 进行线性映射(说白了就是 1x1x1 卷积,来压缩通道数),然后得到θ,ϕ,g 特征
- 通过 reshape 操作,强行合并上述的三个特征除通道数外的维度,然后对 进行矩阵点乘操作,得到类似协方差矩阵的东西(这个过程很重要,计算出特征中的自相关性,即得到每帧中每个像素对其他所有帧所有像素的关系)
- 然后对自相关特征 以列或者以行(具体看矩阵 g 的形式而定)进行 Softmax 操�作,得到 0~1 的 weights,这里就是我们需要的 Self-attention 系数
- 最后将 attention 系数,对应乘回特征矩阵 g 中,然后再上扩 channel 数,与原输入 feature map X 残差一下,完整的 bottleneck
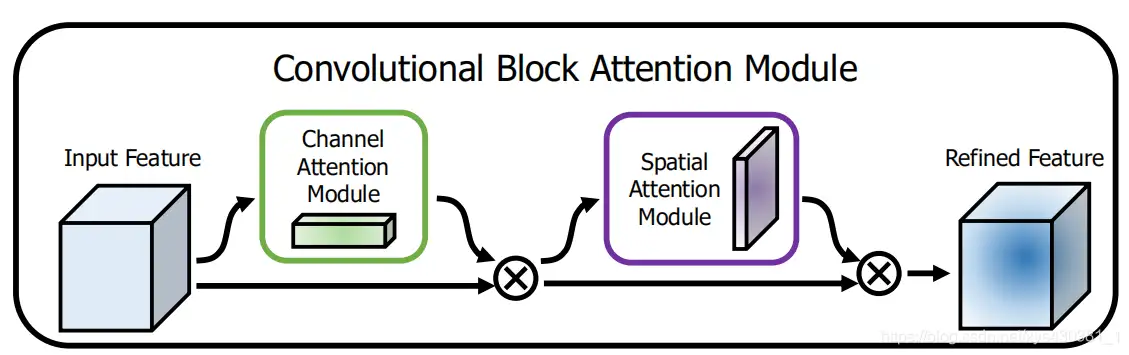
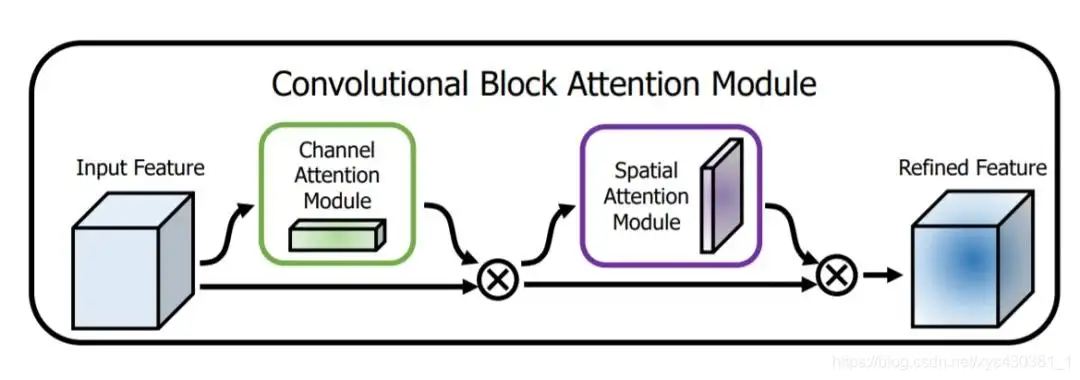
CBAM:Convolution Block Attention Module(通道域 + 空间域)
文中把 channel-wise attention 看成教网络 Look what;而 spatial attention 看成教网络 Look where,所以比 SE Module 的主要优势就多了后者。
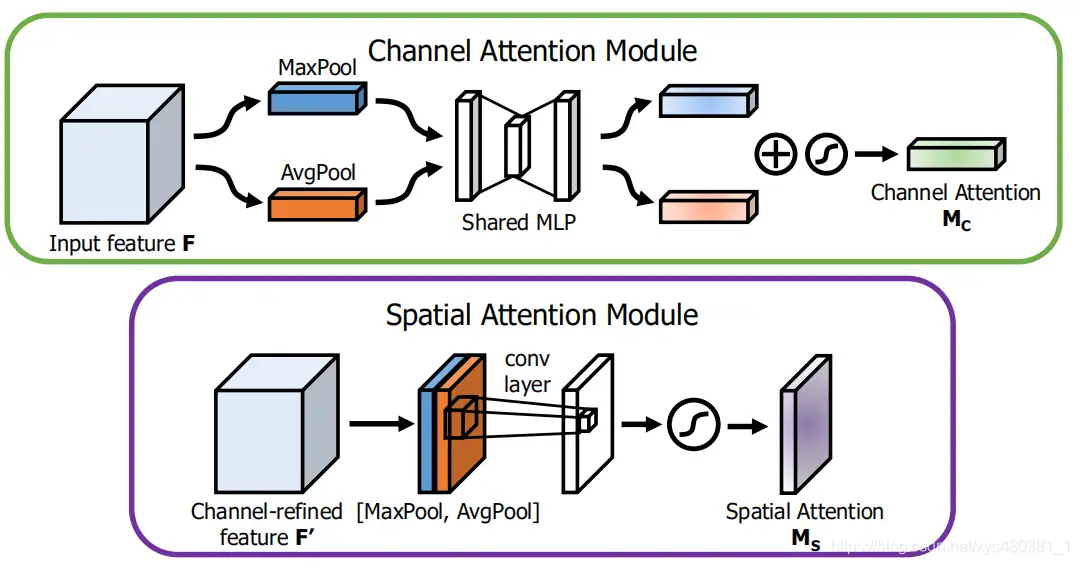
通道注意力公式:
空间注意力公式:(空间域注意力是通过对通道 axis 进行 AvgPool 和 MaxPool 得来的)
CBAW 提出了结合 spatial 和 channel 的模块,如下图所示,在各项任务上也取得很好的效果。
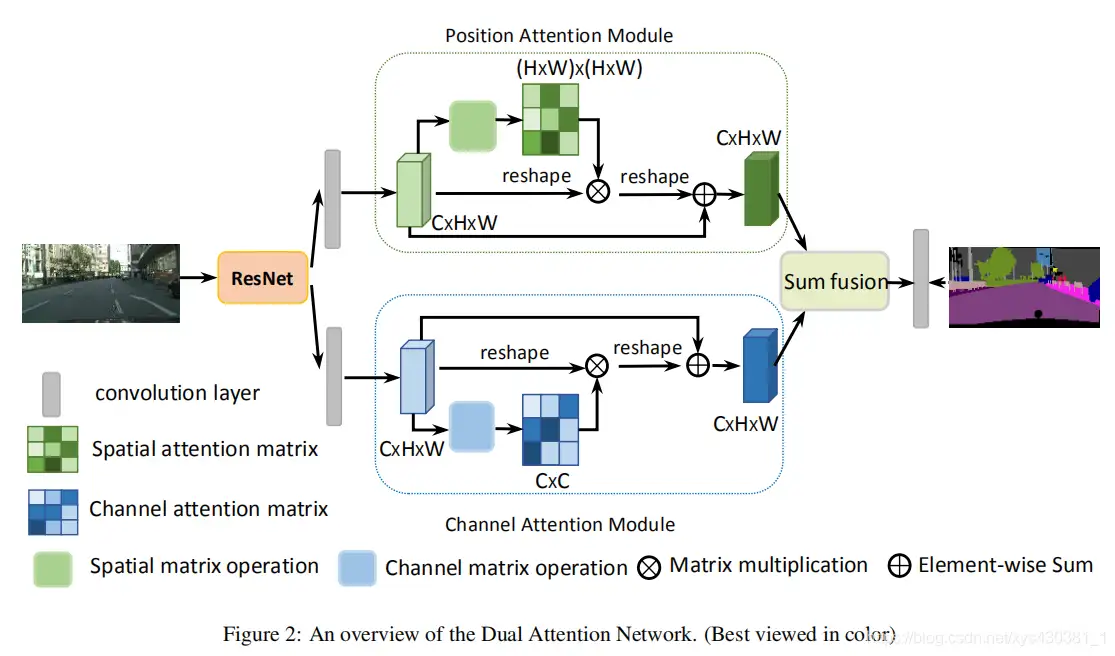
DAnet:Dual Attention Network for Scene Segmentation(空间域 + 通道域)
CBAM 和 non-local 的融合变形:
把 deep feature map 进行 spatial-wise self-attention,同时也进行 channel-wise self-attetnion,最后将两个结果进行 element-wise sum 融合。
 这样做的好处是:
这样做的好处是:
在 CBAM 分别进行空间和通道 self-attention 的思想上,直接使用了 non-local 的自相关矩阵 Matmul 的形式进行运算,避免了 CBAM 手工设计 pooling,多层感知器 等复杂操作。
CCNet
在上面的 DANet 中,attention map 计算的是所有像素与所有像素之间的相似性,空间复杂度为 (HxW)x(HxW),而本文采用了 criss-cross 思想,只计算每个像素与其同行同列即十字上的像素的相似性,通过进行循环 (两次相同操作),间接计算到每个像素与每个像素的相似性,将空间复杂度降为 (HxW)x(H+W-1),以图为例为下:
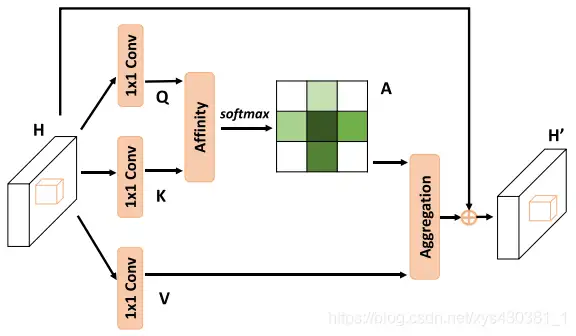
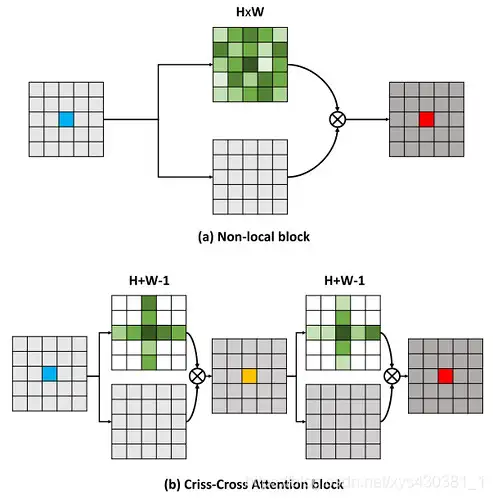 整个网络的架构与 DANet 相同,只不过 attention 模块有所不同,如下图:在计算矩阵相乘时每个像素只抽取特征图中对应十字位置的像素进行点乘,计算相似度。
整个网络的架构与 DANet 相同,只不过 attention 模块有所不同,如下图:在计算矩阵相乘时每个像素只抽取特征图中对应十字位置的像素进行点乘,计算相似度。
时间域注意力(RNN,Recurrent Neural Network)
特意将 RNN 的模型称之为时间域的注意力,是因为这种模型在前面介绍的空间域,通道域,以及混合域之上,又新增加了一个时间的维度。这个维度的产生,其实是基于采样点的时序特征。
Recurrent Attention Model [7]中将注意力机制看成对一张图片上的一个区域点的采样,这个采样点就是需要注意的点。而这个模型中的注意力因为不再是一个可以微分的注意力信息,因此这也是一个强注意力(hard attention)模型。这个模型的训练是需要使用增强学习(reinforcementlearning)来训练的,训练的时间更长。
这个模型更需要了解的并不是 RNN 注意力模型,因为这个模型其实在自然语言处理中介绍的更详细,更需要了解的是这个模型的如何将图片信息转换成时序上的采样信号的:
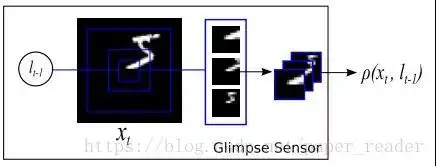 这个是模型中的关键点,叫 Glimpse Sensor,我翻译为扫视器,这个 sensor 的关键点在于先确定好图片中需要关注的点(像素),这时候这个 sensor 开始采集三种信息,信息量是相同的,一个是非常细节(最内层框)的信息,一个是中等的局部信息,一个是粗略的略缩图信息。
这个是模型中的关键点,叫 Glimpse Sensor,我翻译为扫视器,这个 sensor 的关键点在于先确定好图片中需要关注的点(像素),这时候这个 sensor 开始采集三种信息,信息量是相同的,一个是非常细节(最内层框)的信息,一个是中等的局部信息,一个是粗略的略缩图信息。
这三个采样的信息是在 位置中产生的图片信息,而下一个时刻,随着 t 的增加,采样的位置又开始变化,至于 l 随着 t 该怎么变化,这就是需要使用增强学习来训练的东西了。